AI Risk Governance - A Strategic Enabler
"This article addresses the AI Risk hurdle in my Moving Forward with AI article."

Credit: Pla2na
INTRODUCTION
Despite the increasing number of AI projects across organizations, the gap between AI’s feasible capability and enterprise deployment at-scale continues to widen. For financial institutions, the real hurdle is uncertainty around RISK, CONTROL, and TRUST.
AI systems that produce unreliable and indefensible output introduce unacceptable risks for regulated organizations. These risks compound with increasing reliance on third parties to access AI capabilities, ecosystems, and data pipelines that organizations don’t fully control. Recent advances in “agentic AI” architectures that move beyond isolated models to operate across systems and databases, coordinating tasks and reasoning decisions at speed with little human intervention, further amplify risk management challenges.
Effective AI governance has the potential to go beyond regulatory compliance and mobilize the organization to advance AI adoption as a strategic imperative. Organizations can scale AI adoption to deliver value and drive growth while building trust with regulators, stakeholders, and consumers. Doing so requires leaders across business, technology, and risk to develop a shared understanding of AI’s evolving capabilities and limitations in the context of their organization’s strengths and vulnerabilities. This is an execution challenge, with competing priorities across functions.
This primer provides that shared foundation. It synthesizes perspectives from a diverse group of practitioners and decision-makers to help leaders challenge vendor claims, test assumptions, and design adaptive controls as they mature AI capabilities within their organization. We address these critical questions:
Why do traditional risk frameworks fall short for AI adoption? What risks have emerged from AI deployment in practice? How has human-in-the-loop delivered in reality? And what does AI-aware risk governance look like?
Contents
I. UNDERSTANDING AI SYSTEM TYPES AND BUILD CHOICES
II. WHY EXISTING GOVERNANCE FRAMEWORKS FALL SHORT
III. AI RISK THROUGH FOUR LENSES: Model, Data, Deployment, and Strategic & Organizational
IV. AI GOVERNANCE AS A STRATEGIC ENABLER
V. EXTERNAL REGULATORY FRAMEWORKS AND STANDARDS
VI. CONVERGENCE OF DATA AND RISK GOVERNANCE
CONCLUSION: Actionable Recommendations, AI Risk Readiness Self-Assessment, AI Risk Over Model Lifecycle Appendix
Special thanks to the following individuals for sharing their invaluable perspectives:
Ashley Lam, Benton Brown, Bradley Howard, Cara McFadyen, Gary Burke, Hans Lie, Jae Kang, Jonathan Dambrot, Matt Gilham, Navin Ahuja, Rachel Reid, Robert Anderson, Roger Matus, Simon Torrance, Steve Mellor MBCS, Tara Rowell, and several anonymous contributors.
* The views expressed in this paper are those of the individual contributor and do not necessarily reflect the views or opinions of the organization with which they are affiliated.
I. UNDERSTANDING AI SYSTEM TYPES AND BUILD CHOICES
To discuss AI risk effectively, we need to distinguish different types of AI systems and how they are built.
At the highest level:
Rule-based models (since 1970s-1980s): deterministic outputs, human-authored logic, auditable, and fully explainable (e.g., expert systems, business rules engines)
Predictive models (since 1990s-2010s): probabilistic outputs based on statistical learning from data, highly sensitive to data quality (e.g., machine learning models)
Generative AI (since ~2017, scaled adoption since 2022): produces new content based on learned patterns from training data, often opaque in reasoning (e.g., foundation models like ChatGPT)
Agentic AI (emerging since ~2023): system architectures that use AI models to autonomously plan and execute multi-step tasks with minimal or no human oversight
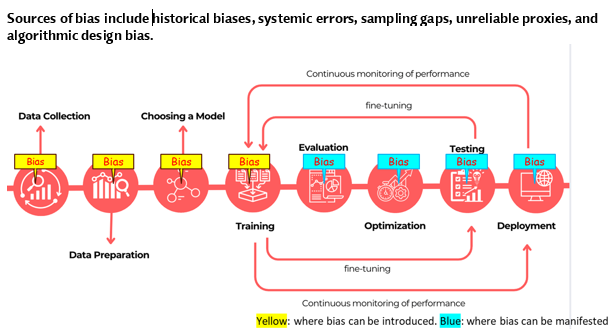
Predictive and generative models introduce new risks that didn’t exist with rule-based systems because they are “trained” on datasets to identify patterns and “infer” outputs based on those learned patterns, including accessing additional knowledge bases and tools in real time. This means risk can enter at any stage of the AI lifecycle, from training to deployment. A model trained on historically biased data, for instance, may produce skewed outputs that amplify those biases, even when the model is functioning as designed. (See Appendix I.)
Build choices also carry risk implications, determining how much control the organization retains from training through deployment at scale.
In-house developed: Full transparency into training data and model architecture and behavior
Fine-tuned models: Large pre-trained models fine-tuned with own domain data while retaining the base model’s capabilities and limitations
Foundation models via application programming interface (API): Third-party models (GPT-4, Claude, Gemini) used as-is and accessed through prompting with minimal control over model behavior
Each poses different levels of risk exposure around data quality, privacy, and consistency. Many organizations initially adopted option 3, sometimes without fully considering risk implications, because APIs were easy to procure. As risk awareness increases, some are moving toward in-house developed or fine-tuned models.
These distinctions shape risk profiles of models, therefore, governance decisions. A rule-based fraud detection model, for instance, has very different risks from a generative model summarizing customer complaints, or an agentic system executing multi-step transactions autonomously.
II. WHY EXISTING GOVERNANCE FRAMEWORKS FALL SHORT
Risk and governance exist to protect businesses by addressing accountability. When systems were rule-based and human-operated, this could be achieved by well-defined rules and clear roles and responsibilities and enforced by auditable decisions. As processes became more automated and handled larger volumes of transactions at faster speed, humans could no longer directly observe every transaction or decision. This led to the introduction of formal controls such as segregation of duties to prevent single points of failure and exception reports to surface anomalies for investigation.
With the rise of enterprise software, the internet, and outsourcing in the 1990s and 2000s, third-parties became part of the control environment and failures became systemic. A vendor’s data breach exposed millions of customer records. A software bug in a payment processor cascaded across banks. An offshore team’s coding error disrupted core operations. While these incidents led to the creation of frameworks such as IT governance, model risk management, and operational risk management, systems were still largely rule-based with verifiable and certifiable outputs, and most organizations structured human and capital resources around it.
The arrival of predictive AI and generative AI, both of which produce non-deterministic outputs, challenges the existing frameworks that are largely built to verify deterministic outputs.
“Traditional systems assume ‘same input, same output.’ But generative AI can produce different outputs even with the same input.” — one risk manager observes
Organizations initially responded by retrofitting existing controls, adding “AI policies,” creating model review boards, and inserting “human-in-the-loop” checks, assuming AI was just another technology to govern — faster and more complex, but ultimately controllable through sufficiently rigorous process. But these retrofitted controls were built for a different problem, and AI risks require all C-suites to step up throughout the AI life cycle from business, procurement, security, and data.
“Traditional risk processes including DevSecOps had no concept of AI threats and risks. Third-party vendor assessments, for example, still rely on questionnaires designed to evaluate static systems, asking whether controls exist, not whether they can adapt to a model that changes its behavior over time.” — Jonathan Dambrot, Cranium AI Security
The following sections examine how these limitations manifest in practice, and what principles must guide governance in this new reality.
III. AI RISK THROUGH FOUR LENSES
Understanding AI risks requires examining the full AI lifecycle from model development through deployment and ongoing operations. The risks that follow apply across all model types but manifest differently depending on what the model does and who, and what, controls it. The question is: what risks matter here, and are controls adequate?
The following four lenses, through decision and ownership, examine: model development risks, data risks amplified by AI, deployment and oversight risks, and strategic and organizational risks.
1) Model development risks: accuracy, consistency, and explainability
The following risks are inherent to how predictive and generative AI systems work. Strong governance and technical controls can reduce them but cannot eliminate them entirely. Leadership needs to understand that some residual risk is structural when assessing exceptions.
Bias
Bias can enter at any stage of AI model training and deployment from either algorithmic design and/or through training datasets that contain historical biases, systemic errors, sampling gaps, and unreliable proxies that can skew a model’s predictions. Examples of bias include flawed classifications that disadvantage a demographic group in credit scoring or in an underwriting model that misprices risk according to zip codes.
When models drive decisions on creditworthiness, insurance eligibility, and fraud classification, biased output exposes the organization to regulatory, reputational, and ethical risk. For a more detailed discussion of bias in AI-driven decision-making, refer to Bias+in+AI+-+Whitepaper+vFinal.pdf
Data drift and model drift
Data drift occurs when real-world data feeding a model changes over time. A fraud detection model trained on pre-pandemic transaction patterns, for example, may underperform as spending behavior permanently shifts post-COVID, even when the model itself hasn’t changed.
Model drift happens when the predictive relationships a model learned during training weaken over time due to data drift or other changes in real-world conditions, causing output quality to deteriorate. For example, a predictive sales model may drift when customer behavior evolves beyond what its training data captured; a generative model may drift when the domain it operates in moves beyond what it originally learned.
Data drift often precedes and causes model drift. Both risks require ongoing monitoring and periodic retraining or fine-tuning to ensure models remain aligned with real-world conditions. These risks are especially challenging when organizations access foundation models via API, with little visibility or control over when or how the underlying model is updated by the provider.
Explainability gaps
Explainability and defensibility are paramount for regulated industries to satisfy audit and regulatory requirements. Unlike traditional systems that produce consistent and auditable outputs, AI models, particularly foundation models, often produce outputs that are not traceable to specific data points or logic. Even when interpretability tools identify which inputs the model weighted most heavily, model validation teams cannot always verify that the model behaved to the standard regulators and auditors require.
This creates practical problems: organizations cannot resolve customer disputes with clear explanations, and audit trails lack the transparency that existing risk frameworks require. This is particularly challenging with foundation models accessed via API where organizations do not have visibility into training data or algorithmic logic. Some organizations have responded by limiting foundation model use to low-risk applications or requiring AI-generated outputs to be subject to human review.
Output inconsistency
Predictive and generative AI models, being probability-based, can produce different outputs from the same dataset, and the same prompt can generate different summaries or recommendations each time it runs. Even though prompting techniques (clearer extraction rules; prohibiting filling in values without evidence) can reduce inconsistency, this is inherent to how these models work, not necessarily a programming bug.
This introduces risk exposure for processes that require consistent application of standards, such as compliance checks or credit decisions. Audit trails become unreliable, quality checks are impossible to perform, and it’s difficult to determine whether the model is degrading or is simply exhibiting normal variation. Expecting probability-based AI to match the consistency of rule-based systems is impractical.
Hallucinations
Specific to generative AI models (including natural language, image, vision, and speech/audio), hallucinations are confident-sounding but factually incorrect outputs that arise when the model is trained on incomplete or biased data, and when model design prioritizes fluency over accuracy and doesn’t have an “I don’t know” response built-in.
Hallucinations can also occur when a prompt gives insufficient context or asks the model to extrapolate beyond its training data. A recent high-profile case involved a report produced for the Australian government that referenced non-existent academic research papers and a fabricated quote from a federal court judgment.
Techniques such as Retrieval-Augmented Generation (RAG) have been adopted since 2023 to reduce hallucination in enterprise adoption with mixed results in practice.
2) Data risks amplified by AI
The “garbage in, garbage out” principle is more critical than ever when AI involves unstructured data such as emails, documents, and meeting transcripts, and drives autonomous decisions at machine speed, making errors harder to detect.
“Data is everything for AI.” — a Chief Risk Officer
Matt Gilham of Whitelk Consulting identifies three critical failure points in how data flows through AI systems, using fraud detection as an example:
Data silos — critical information trapped in unconnected repositories, preventing a coherent view of customer risk.
Quality erosion — fraud-tainted transactions absorbed into models as if they reflect normal customer behavior.
Weak controls — allowing contaminated data to flow through live systems, undermining model reliability.
Data accuracy and integrity risks are further compounded when data management functions are nearshored or offshored, increasing the distance between data stewards and the business context needed to detect and remediate errors. This further complicates the data transfer and processing concerns for AI deployment.
Data contamination risk extends beyond individual organizations. As AI-generated content proliferates online, it increasingly pollutes the datasets used to train future models.
“There is a real systemic risk that AI models do not detect false signals created by AI. As these false signals contaminate more datasets, the value of the datasets decreases, and the compounding effects of model errors lead to significant model collapse or disutility.” — Benton Brown, risk and regulatory practice leader
A degradation cycle emerges where models trained partly on synthetic data generated by AI produce lower-quality outputs, which in turn contaminate the next generation’s training data.
One organization discovered that an internal April Fools’ communication was ingested by their AI system as factual data. It took months to fully remediate, demonstrating how difficult contamination is to detect and remove. This episode also points to a data retention challenge. Traditional retention policies assume a clean lifecycle of using, archiving, and deleting data. But when a model has learned from a dataset, the data “lives on” in how the model behaves. And every AI interaction generates its own logs of inputs, outputs, and decisions that organizations must retain for audit and regulatory scrutiny while limiting how long sensitive information sits exposed.
Ultimately, AI data risk leads to decision risk.
“AI skips the dashboard into an action. When bad data drove bad dashboards, humans could catch errors before acting. When bad data drives autonomous decisions, the error and the harm occur simultaneously.” — Bradley Howard, Endava
Who is responsible when AI-driven decisions cause harm? Many organizations point to human-in-the-loop (HITL) controls as the answer. But has HITL delivered on its promise? We will examine this more closely under strategic and organizational risks.
3) Deployment and oversight risks
These risks emerge when high-potential AI pilots move from controlled environments into production. They sit between technology and operations and require clarification of ownership to manage effectively.
Automating flawed processes
Organizations risk embedding inefficiencies at scale when they over-trust generative AI in high-stakes decisions while under-utilizing predictive AI, which is well-developed for certain tasks. Automating broken business processes with AI or deploying agentic AI without fixing underlying workflow problems involving decisions, then placing humans to catch and remediate failures, is a design flaw.
“Humans should not exist primarily to compensate for poor process design with unclear decision rights.” — Jae Kang, risk & data management executive
Security controls bypass
Rapid advances and evolving economics of cloud computing and data sourcing have accelerated AI adoption, overwhelming existing controls. Models are going directly into dominant hyperscaler cloud (AWS, Microsoft Azure, Google Cloud) and development pipelines without being treated as software, which normally goes through cyber and data security controls that would catch vulnerabilities before production.
“Security of data and systems has to be baked in from day one at the code level.” — Tara Rowell, AI engineer
Security risk is heightened when AI is used to generate code (i.e., vibe coding), when a pilot or prototype can look as if it’s working but may not perform well at scale if security holes or other architectural limitations exist. When an AI agent is given access to tools or databases to act autonomously, it introduces vulnerability beyond a single incorrect output. Recent incidents have shown how quickly an autonomous AI agent can gain unintended access with no code change and no audit trail.
Inadequate quality assurance (QA)
Traditional QA assumes same input, same output, and that if a system passes a test today, it will behave the same way tomorrow. Probabilistic AI systems do not work that way, making passing a single test inadequate for assurance. Validation must be repeated continuously, edge cases must be stress-tested, and the operating model must account for the possibility that the system will behave differently under conditions not encountered during development. This includes negative testing to confirm the system does not produce outputs that violate guardrails, frequently conducted by a “red team” whose purpose is to challenge the model with adversarial scenarios.
These risks can only be mitigated through ongoing structured output validation, mandatory human review, and transparency about the model’s limitations. This is not easy and has led to design decisions that require users to treat AI output as a draft, subject to review and approval.
Interoperability and integration
Many promising AI pilots fail to deliver ROI at scale because teams struggle to operationalize in existing infrastructure that was never designed for probabilistic outputs. This is a particularly acute problem in organizations where “patchwork” integrations in mergers and acquisitions over the years accumulate sizable technical debt.
Common integration challenges include data pipelines that cannot produce information at the volume or speed AI requires, approval for access to sensitive data that were not anticipated during workflow design or pilot, unclear guidance on when to trust AI outputs or require human review and how to handle exceptions, and legacy systems that lack the infrastructure AI demands, forcing a choice between costly overhaul or limited deployment.
These challenges are compounded when integrating foundation models that organizations don’t fully control. Except for projects intended purely for learning and experimentation, integration requirements and production data access should be evaluated before a pilot is approved.
Model ownership and accountability across geographies
For global institutions, model ownership becomes more complex when the same model is deployed across multiple jurisdictions. A transaction monitoring model may be governed by different regulatory regimes, data residency requirements, and risk appetites across regions, yet managed as a single system. This creates ambiguity around who owns the risk, who is accountable for model performance in each jurisdiction, and who has authority to intervene when outputs require remediation. Efficiency gains from centralized deployment can erode quickly with governance responsibilities across borders.
Non-technical behavioral risks in deployment
Data leakage occurs when an employee or AI agent includes sensitive data in prompts or uploads PDFs containing proprietary information, unaware of or disregarding where that data flows or how data will be used. The well-known case of Samsung engineers inadvertently sharing proprietary source code through an AI chatbot illustrates how quickly confidential information can leave an organization’s control without adequate input guardrails.
Sensitive data handling policies are now commonly seen, governing what data can be entered, who can access it, and where it’s stored, but remain poorly controlled in many organizations. For example, when meetings involving confidential and sensitive data are transcribed, where the data is stored can create significant risk exposure.
Shadow AI refers to AI models deployed outside formal IT governance and security oversight, bypassing procurement, security review, and model risk management entirely. This is often driven by decentralized, business-led functions or by individual employees using personal API keys.
Mitigating these behavioral risks requires clear policies, training, and embedded controls in infrastructure and workflows, such as AI system registries and mandatory security reviews before deployment that encourage experimentation without sacrificing oversight.
Third-party risks amplified by AI
Most AI deployments rely on third parties such as model providers, cloud platforms, data vendors, and systems integrators, and AI capabilities are increasingly embedded in core enterprise platforms. In a widely circulated open letter to suppliers, JPMorgan Chase Chief Information Security Officer Patrick Opet warned: “There is a growing risk in our software supply chain, and we need your action,” recognizing risk across increasingly interconnected ecosystems.
The traditional questionnaire-based vendor risk management process is point-in-time, lacking AI-specific questions that assess the technical composition of a system (e.g., model, data, dependencies) or identify how data is processed and retained, increasing privacy and regulatory exposure.
Vendors may update models or modify training data without notice, further undermining established validation and audit protocols.
Visibility into vendor controls for explainability, bias, and other guardrails is essential and increasingly incorporated into agreements. Equally important is intellectual property (IP) ownership and liability for AI-generated outputs. This requires risk oversight beyond onboarding due diligence to include continuous monitoring of third-party development choices and post-deployment operational practices.
4) Strategic and organizational risks
These risks require board-level and C-suite decisions about strategy, resource allocation, and workforce development.
Fragmented data
Data siloed across legacy systems is one of the most common barriers to AI adoption delivering meaningful value at scale. Without a unified data foundation, organizations are not only limiting AI capability today, but deferring a problem that compounds as AI adoption grows. By contrast, organizations that have unified internal data and sourced external databases are already seeing results: identifying relationships between individuals and organizations has enabled discovery of coordinated fraud rings, flagging anomalies with greater accuracy that reduces leakage and improves customer retention.
This is more than a technology decision and requires high-level sponsorship to drive the fundamental reimagining of data infrastructure that makes it possible.
Resource allocation imbalance and execution gaps
Leaders should ensure the funding for AI deployment includes adequate resources for risk management.
“While investment in AI technology is growing rapidly, investment in risk governance infrastructure and capabilities lags significantly behind.” — Anonymous
A BCG survey found that about 90% of CEOs believe by 2028, AI will redefine what success looks like, with companies reshaping critical workflows and, for many, inventing entirely new business models. However, the farther the distance from the C-suite, the less confident the executives are in AI’s eventual payoff, dropping from 62% for CEOs to 48% for non-tech executives outside the C-suite.
How organizations execute strategic moves quickly while balancing resources and building adaptive controls points to AI adoption as a leadership execution challenge.
Change management and workforce readiness
Executives often publicly state that successful AI implementation depends more on people and change management than on technical capabilities, yet many organizations still allocate disproportionately more budget and attention to model development than to preparing employees. The challenge ranges from task-level training (equipping employees to take on an active role in governing AI-augmented outputs) to strategy-level decisions on roles and accountability realignment between human and digital workers.
Managing resistance to how AI changes work, and building a culture of adaptability and trust, is equally critical and often underinvested. When AI deployment causes job displacement, transparency upfront and real opportunities for retraining and redeployment go a long way in building trust and engaging employees.
Human-in-the-loop (HITL): promise vs. reality
In conferences and webinars, “Human-in-the-loop” (HITL) is often cited as the control mechanism that allows AI adoption to meet regulatory and societal expectations for accountability, especially in high-risk, high-impact areas such as loan or insurance claim approval. In practice, “It is far more fragile than we often admit. says Cara McFadyen of Ooshka Consulting. “Without the right skills, incentives, and ethical framework, HITL risks becoming a comforting illusion, one that allows bias and risk to move faster and further than before AI.”
One HITL builder observed that humans in the HITL process were often suspicious at first and monitored the system closely. Fairly quickly, however, humans learned to trust AI. But that trust can easily become overreliance, quietly built into HITL processes over time.
HITL proponents assume that any human reviewing output is sufficiently skilled, independent, and empowered to challenge it. In reality, many workers asked to “sanity check” AI outputs do not fully understand the underlying decision and are often under time pressure. This leads to automation bias: outputs are accepted not because they are correct or fair, but because they look credible.
One risk manager in a top financial institution shares that refining prompts and adding more rules does not eliminate output variability. As a result, control procedures such as review and exception correction often become the bottleneck.
It’s also unrealistic to assume that humans can keep up with the volume of AI outputs that require review. Organizations may try limiting AI output to the speed humans can handle, but for many tasks AI is both faster and more accurate than humans alone.
The limitation of human oversight is even more profound when it comes to bias, which is likely already embedded in historical underwriting decisions due to human judgement, commercial pressure, and legacy assumptions. That bias will be perpetuated by the same humans now validating or subtly steering AI outputs, and will be amplified at scale if not detected and mitigated in model training and design.
With these limitations in mind, particularly for decisions in which context and experience matter, AI augmenting expert decisions is still the norm. “Where HITL does work is when it is supported by culture, governance, and capability, not when it is treated as a tick-box control,” Cara McFadyen points out. “HITL needs to be designed as an organizational capability.”
Effective HITL starts with clear direction from the top on where AI may inform decisions and where AI must not decide, grounded in the organization’s risk appetite and governance priorities. Equally important are decisions on how to prepare and recruit employees for AI-assisted decisions and what HITL training should look like.
A trend is emerging to use agentic compliance controls where compliance certification will involve ever-increasing degrees of automation. Organizations are beginning to supplement HITL with technical controls including audit logging, drift detection, and real-time policy guardrails.
Skill gaps and career implications
As Jonathan Dambrot of Cranium notes, skill gaps exist at multiple levels: security teams lack the AI expertise to assess model risks, risk managers lack the technical depth to evaluate AI systems, and business leaders lack sufficient AI literacy to ask the right governance questions.
These gaps compound across the workforce. As a chief risk officer observed, the workforce now has a small group of experts continuously pushing the frontier building tools, another group using tools effectively, with the majority at a basic skill level with no clear path to develop further, leaving adoption spotty and amplifying organizational risk. These divisions can increasingly shape career trajectory, creating inequality within organizations that leaders need to consider strategically.
IV. AI GOVERNANCE AS A STRATEGIC ENABLER
Simon Torrance ofAI Risk asked: what needs to be true for AI governance to become a “strategic enabler,” not just a compliance function? We offer three conditions to move AI governance from a cost center to a function that reduces risk and enables growth in ways not previously possible.
1) Business ownership of risk outcomes
AI risk governance is typically delegated to compliance or technology, with business leaders signing off on policies without truly understanding business and operational implications. Business leaders from the CEO to P&L owners need to make risk and governance decisions that impact their bottom line based on business context. They should participate in model approval decisions, understand the limitations of the AI models they depend on, and be accountable for deployment results. It starts with equipping business leaders with the knowledge, vocabulary, and evaluation criteria to participate in these decisions.
2) Governance funded as an organizational capability
AI governance requires investment in tooling, talent, and infrastructure such as continuous model monitoring, automated drift detection, real-time policy enforcement, and audit at machine speed. Investment must keep pace with the systems it is meant to govern. Investment in talent may include upskilling and supporting managers and empowering front-line workers to challenge AI outputs and continuously adapt controls.
3) Controls at the speed of AI
AI systems can make decisions in milliseconds. Agentic systems can chain multiple decisions in sequence before a human is aware any action was taken. Traditional governance operates on the cadence of quarterly reviews, annual audits, and committee approval cycles. This mismatch requires a fundamentally different control architecture.
As discussed earlier in the HITL section, when human review cannot keep pace with AI output volume, it forces a governance decision to either slow AI outputs to human speed as appropriate for high-stakes decisions, or invest in automated controls with humans governing the governance system, setting thresholds, reviewing exceptions, updating policies, and deciding when the system should stop.
V. EXTERNAL REGULATORY FRAMEWORKS AND STANDARDS
Organizations typically align their internal governance with external regulatory frameworks and professional standards in defining and mitigating AI risk. Some may choose to develop a unified AI governance program that makes it easier to respond to regulatory inquiries and exams. Others that already have strong policies and controls addressing areas commonly affected by AI (such as model risk, operational risk, data privacy risk, cybersecurity risk) may incorporate AI into existing policies and controls to avoid duplication and confusion.
Data quality, technical and process lineage controls, and accountability structures for AI decisions are common governance challenges. The following frameworks directly address these controls:
Data Management Body of Knowledge (DAMA-DMBOK) by Data Management Association International, now in its 2nd edition, covers 11 knowledge areas of data management and addresses data quality and lineage gaps that undermine model reliability and auditability. AI model performance is fundamentally dependent on data quality.
AI Risk Management Framework (RMF) by National Institute of Standards and Technology (NIST) released in January 2023, is a voluntary but influential framework addressing trustworthy AI through four core functions: Govern, Map, Measure, Manage. It complements data governance and addresses AI system risk, safety, and accountability across the AI lifecycle.
While some AI regulations, such as the EU’s AI Act, explicitly address safety, transparency, accountability, and human oversight around AI, many existing laws in data privacy, consumer protection, finance, healthcare, and employment already apply to AI use. Regulators will need to determine how much trust can be placed on AI models used to supervise AI output, and whether AI can be relied upon to triage the volume of decisions down to the more ambiguous or sensitive cases that require human judgement.
Privacy in the age of AI
AI introduces privacy challenges that existing data protection frameworks were not designed to address. Once data is used to train a model, it becomes embedded in the model's learned patterns. A customer's right to be forgotten may be technically unenforceable. Data collected for one purpose may be repurposed to train models without clear consent.
In response, regulations such as the EU AI Act, Colorado's AI Act, and California's new CCPA rules for automated decision-making all introduce AI-specific privacy obligations, and "machine unlearning" is emerging but is in its infancy.
Regulatory clarity is a powerful enabler of innovation and risk mitigation, as evidenced by the momentum created by Japan’s AI Promotion Act in May 2025 and subsequent discussion papers by JFSA. It also speaks to the advantage of engaging early with regulators and industry bodies to help shape frameworks that are protective of consumers while enabling new business.
Waiting for AI-specific regulation is itself a risk. In the UK, for example, the FCA has signaled it will not introduce AI-specific rules, relying on existing principles-based frameworks that already require firms to manage risks appropriately and avoid customer harm. Organizations that delay governance until prescriptive rules emerge are likely to face greater scrutiny under frameworks already in place.
VI. CONVERGENCE OF DATA AND RISK GOVERNANCE
AI is only as good as the data powering it. As regulatory frameworks such as NIST AI RMF and the EU AI Act increasingly treat data risk as integral to AI system risk, organizations should consider streamlining data and risk governance through joint governance committees or unified accountability frameworks. Fragmented copyright, data protection, and content-related laws across jurisdictions further complicate AI risk management but reinforce the interdependence of data and risk oversight.
Ultimately, governance only matters if controls can be translated into everyday decisions, in plain language: what data an AI agent can access, what actions it can take, what must be logged, and when a human must grant approval. Achieving this requires data governance and risk management to operate as an integrated function.
CONCLUSION
The probabilistic nature of AI systems, especially those informing autonomous decisions, has rendered traditional governance frameworks built for deterministic, human-operated controls inadequate. Biased credit decisions and automation bias are predictable consequences of deploying probabilistic AI that cannot be solved by retrofitting existing controls.
AI governance has the potential to become a strategic enabler if funded as an organizational capability, operating at the speed that AI demands, and owned by business leaders with the context to make risk-informed decisions. This is not easy, and those who do the hard work gain a real advantage - the Evident AI Insurance Index shows that top-performing insurers prioritize transparency and ethical AI development, linking performance to strong governance and leadership.
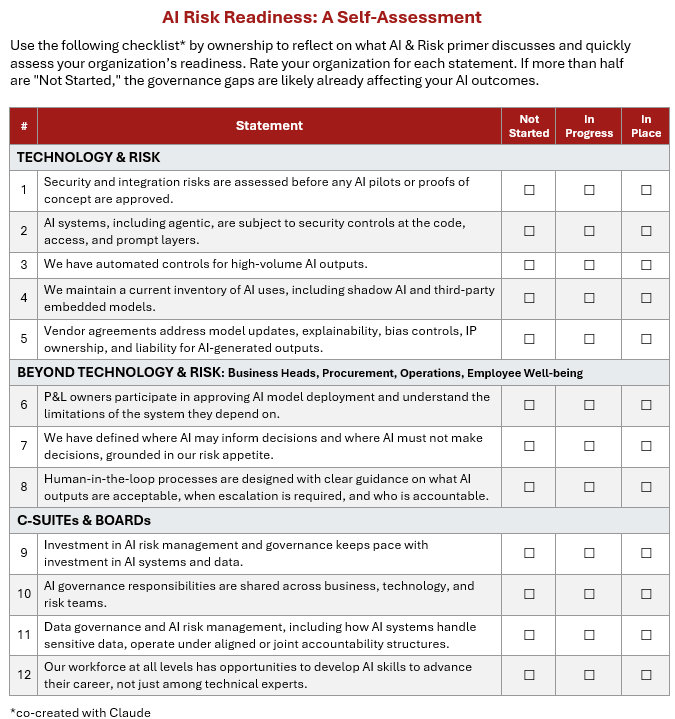
Actionable Recommendations:
i. Align business, technology, and risk leadership
AI risks span model-level accuracy, data integrity, third-party dependencies, human oversight limitations, and execution gaps. Effective governance requires ongoing collaboration across functions to continuously challenge vendor claims, monitor model outputs, and make joint risk-informed decisions. AI governance should not be delegated to a checklist or isolated in a single function, especially considering functions are often siloed due to different priorities, the tension between speed and control, and complex issues such as incentive structures. Overcoming silos and strengthening cross-functional collaboration is a leadership priority for effective AI risk mitigation. For global institutions, this includes clarifying model ownership and risk accountability across jurisdictions.
ii. Build and maintain an AI inventory
Organizations should build and maintain an inventory on what each AI system does, who owns it, what data it touches, and what controls are in place, including shadow AI and third-party embedded models. This is the foundation on which everything else depends, and goes beyond compliance to enable strategic decisions. Tools are emerging to accomplish this efficiently.
iii. Put security and integration first
Most failures at scale are preventable if security and integration risks are assessed before a pilot is approved. Meanwhile, security must be designed from day one at the code level and the access control and prompt layer to “keep the front door protected” as one security expert puts it. This is particularly critical as organizations move from single models to agentic architectures where the attack surface expands significantly. Zero Trust principles (Never Trust, Always Verify) is a useful guide for managing digital identity, data access, and autonomous decisioning, especially with third parties, though balancing risk with practicality is necessary.
iv. Build adaptive oversight and invest in human-AI readiness
AI systems need continuous monitoring and finetuning to maintain model performance over time, and human-in-the-loop controls only work when workers have the skills, authority, and incentives to do the right things. This requires leadership commitment to explainability standards, clear accountability, auditable decision trails, and investment in upskilling the workforce, from retraining experienced employees to supervising AI-augmented workflows, to building AI literacy at all levels. This includes defining and continuously revisiting where AI informs decisions and where humans must decide as AI capabilities mature.
v. Invest in controls that operate at the speed of AI
The volume and velocity of AI-driven decisions are rapidly exceeding what human-centered controls alone can handle. As agentic AI architecture introduces autonomous decision-making across systems, organizations should invest in solutions such as automated monitoring, continuous model validation, and real-time policy guardrails, with humans managing the governance system, not checking every individual AI output.
vi. Align data governance and AI risk management
Data risk and AI system risk are becoming inseparable (consider data contamination and model drift). Organizations should consider integrating data governance and risk frameworks into a unified accountability structure, including how AI systems handle sensitive data from training through deployment. This streamlining will accelerate successful AI deployment at scale and build trust with regulators, customers, and stakeholders.
Those that act on these recommendations will gain an early-mover advantage in scaling trustworthy AI through strong governance.
Appendix I: AI Risk Over Model Lifecycle
Bias can enter at any stage of AI model training and deployment. Using bias as an example, the following graph describes how a predictive AI model is trained and where bias risk can occur.
“AI is like a kindergartner—it absorbs everything without knowing what’s right or wrong. If you don’t actively teach it, you risk perpetuating harmful patterns already present in your data.” — John Standish, Charlee.ai
For a more detailed discussion about Bias in AI-Driven Decision Making, see: Bias+in+AI+-+Whitepaper+vFinal.pdf
Interested in working through cross-function and cross-culture AI governance? Get in touch.
* Ichun Lai founded Propel Global Advisory LLC focusing on accelerating the purposeful and responsible AI adoption in financial services